This article is mostly a high-level overview of the Astorisc architecture, do not expect implementation tricks and gory details in here.
As I said in the presentation, I'd like to make Astorisc a pipelined processor. But what does this actually mean? I could send you to the article on Wikipedia, but I may as well try and explain it myself.
In a nutshell, pipelining will make the processor execute the instructions in a series of steps (or stages), each step running in a different unit, allowing processing multiple instructions in parallel.
The pipeline in Astorisc will be the well documented canonical 5-stages pipeline, that is perfectly suitable for a RISC architecture:
- Instruction Fetch
- Instruction Decode and register load
- Execute
- Memory access
- Register writeback
How the pipeline works
At each clock cycle, the instruction will advance to the next unit of the pipeline, keeping all the stages busy. At least, that's the theory. In practice, there are situations where an instruction must be delayed until the resource it needs becomes available.
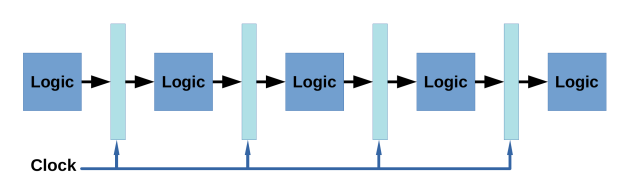
When the clock ticks, each intermediate register will store the result of the unit before it, and make it available to the next unit in the line, keeping its value stable until the next cycle.
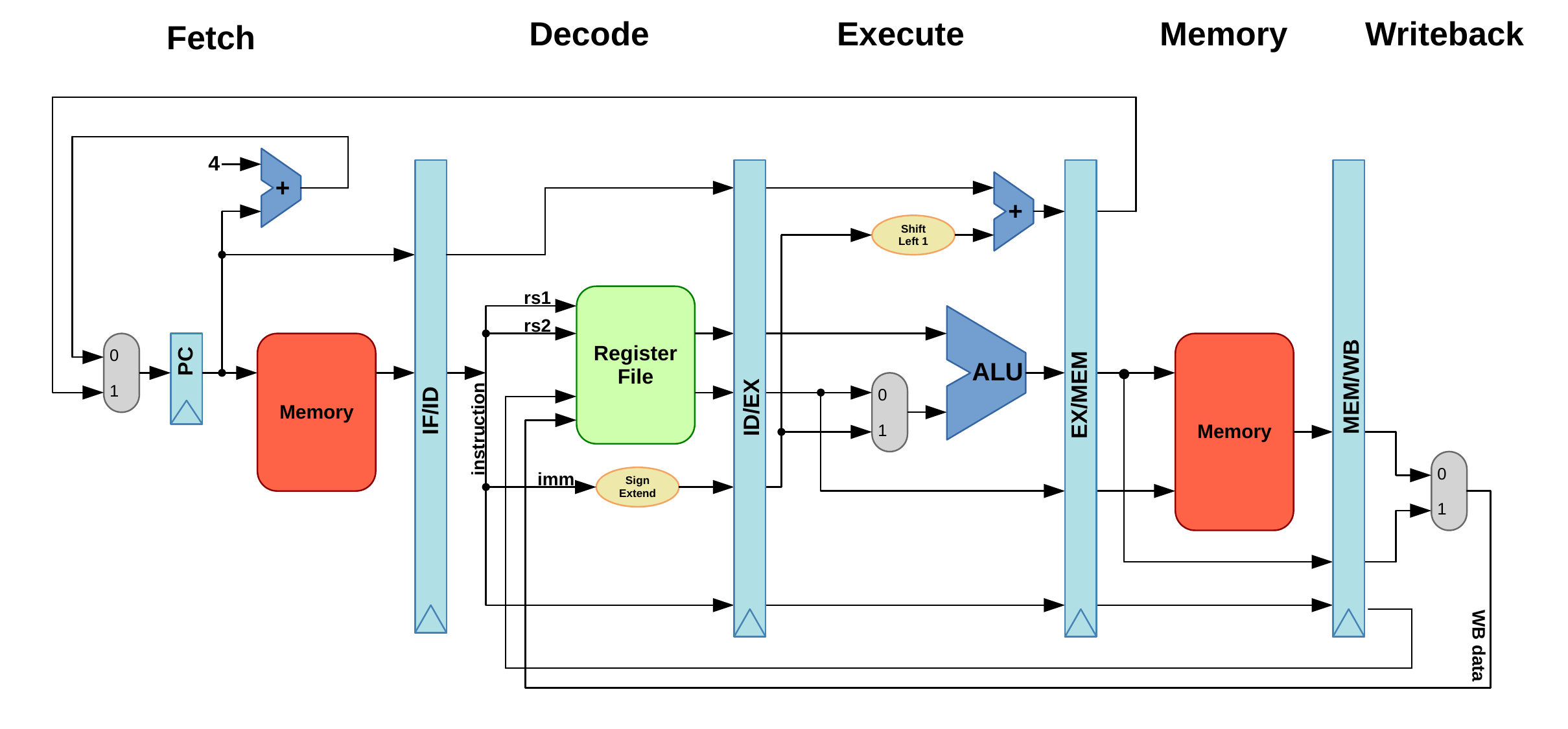
The pipelined RISC-V datapath
Here is an extremely simplified datapath diagram for our pipelined RISC-V
processor.
Pros and cons ?
The main advantage of a pipelined architecture is that each step, taken individually, is comparatively simpler and needs a much shorter amount of time to execute, meaning the processor can run at a higher clock speed.
The downside is that the processor gets more complex, because of all the intermediate registers and the control logic.
Hazards
In a pipelined CPU, an instruction starts being executed before the previous one is finished. That can cause problems, for instance when the second instruction needs the result of the first one before it is actually available. Those problematic situations are called hazards.
I will not go into the details of the various types of hazards, nor when or why they happen. Instead, I will shortly describe the solutions that I can implement to resolve the issues.
- Stall: This is probably the easier solution. When an instruction needs a previous instruction's result that is not yet available, make it wait until it is. In some situations, there is just no way around it.
- Bypass: A more complex, but more efficient solution, is to provide an alternative path for the data to be routed immediately when it is available. I intend to implement this operand forwarding at least at the Execute stage.
Note that I do not intend to implement out-of-order execution ;-)
There is also the question about accessing the memory that can happen at both Fetch and Memory stages. Probably the easiest way to solve this issue will be to deny the fetch when an instruction accesses the memory. This is a bit like a stall, although it happens at the very first stage of the pipeline, so nothing actually stalls.
For the jumps and branches that are taken, I will need a way to discard the instructions that have already been loaded into the pipeline but must not be executed.
But how to do all that?
In future articles, I'd like to go into the details of some of the components that I've shown as simple boxes in the diagram above. The ALU symbol may look quite simple, but the reality far from that!