Compression d'image grace au VQ
et recherche de similarité entre deux images
chrisbk@ifrance.com
preambule
Avant toute chose, je tiens a dire que tout ce que je sais sur le VQ vient d'un article trouve sur gamasutra.
Alors :
- vous avez lu et vous avez tout compris : vous pouvez sauter la partie VQ
- vous avez lu et vous avez rien compris : allez, session de ratrapage
index
- VQ
- Qu'est ce que le VQ ?
- Quantisons une image..
- tranformer les elements de l'image en vecteur a 12 dimensions
- calculer le codebook
- condition d'arrets
- compresser l'image
- choix de la pattern
- Resultat de la compression
- Performances
- Taille du codebook : que choisir ?
- Recherche de similarité entre deux images
- introduction
- entropie marginale
- entropie jointe
- interpretation
- Conclusion
VQ ca veut dire vector quantization (notez que lesdit vecteur peut etre de n'importe quelle dimensions, 3 12,50...)
L'idee ca va etre d'approximer un ensemble par un autre ensemble, plus grossier que le premier (tout en essayant de l'approximer au mieux). Etant donné que ce second ensemble sera plus "grossier" que le premier, alors il prendra moins de place sur disque.
Ce qui est bien
Note : pour la suite du document, les images sont stockés en 32bpp, 8 bits pour chaque composante. ce qui nous fait donc des valeurs allant de 0 a 255. Non que ce soit une nécéssité...
Quantiser (quantifier ?) directement les valeurs des composantes n'auraient que peu d'interęt, ce que nous allons plutôt faire, c'est quantiser un groupe de pixel (2x2 par exemple)
A trois composantes par pixels, cela nous fait un vecteur ŕ 12 dimensions. Pas de panique, tout ce que l'on va faire avec ces vecteurs, c'est les additionner, multiplier par un scalaire , calculer la norme. Rien de bien compliqué, męme avec 12 dimensions.
L'image compressée se décomposera en deux parties : un codebook, et une suite d'indice. (un peu le meme principe que les images 8bits indexees avec la bonne vieille palette).
Plus le codebook est gros, plus l'image compressée sera fidčle ŕ l'originale ( j'espčre ne pas avoir ŕ expliquer la contrepartie de l'affaire)
La suite d'indice dira quel élčment du codebook doit on utiliser pour le block de pixel courant (une entrée dans le codebook sera donc un vecteur a 12 dimensions dans notre cas).
Le problčme étant donc de calculer ledit codebook pour avoir une qualité optimale.
Pour se faire on va procéder en plusieurs étapes :
1) tranformer les élčments de l'image en vecteur a 12 dimensions
2)calculer le codebook
3)compresser l'image avec l'aide du codebook
Bon, la c'est assez simple .
imaginons les structures suivantes
struct SQuant
{
float data[12];
};
struct RGB
{
unsigned char r,g,b;
}
On va convertir chaque block de pixel en SQuant .
int width,height; //taille de l'image
RGB *bitmap //pointeur vers ladite image
int widthQ = width / 2;
int widthQ = height / 2;
SQuant * quant = new SQuant[widthQ *heightQ ]; // on a donc autant de SQuant que de block de 2x2 pixels
// Attention ! ces SQuant ne sont pas notre codebook !
SQuant * tmpQuant = quant ;
for (int i = 0 ; i < height;i+=2)
{
for (int j = 0 ; j < width;j+=2)
{
tmpQuant->data[0] = (float)bitmap[i][j].r;
tmpQuant->data[1] = (float)bitmap[i][j].g;
tmpQuant->data[2] = (float)bitmap[i][j].b
tmpQuant->data[3] = (float)bitmap[i][j+1].r;
tmpQuant->data[4] = (float)bitmap[i][j+1].g;
tmpQuant->data[5] = (float)bitmap[i][j+1].b
tmpQuant->data[6] = (float)bitmap[i+1][j].r;
tmpQuant->data[7] = (float)bitmap[i+1][j].g;
tmpQuant->data[8] = (float)bitmap[i+1][j].b
tmpQuant->data[9] = (float)bitmap[i+1][j+1].r;
tmpQuant->data[10] = (float)bitmap[i+1][j+1].g;
tmpQuant->data[11] = (float)bitmap[i+1][j+1].b;
tmpQuant++;
}
}
Si vous avez bien tout compris, chacun de nos "SQuant" contient donc un bloc de pixel, dont les valeurs on ete convertie en réel, histoire d'avoir de la precision dans nos calculs.
Phase 1 terminée
On passe a la deux.
Lŕ on va se créer notre codebook.
On va se faire une autre chtite structure
struct SCodebookentry
{
SQuant vector;
SQuant sum;
SQuant farthest;
int nbhit;
float maxDistance;
};
(pas de panique j'explique tout apres)
SCodebookentry *codebook = new SCodebookentry[codebookSize];
memset(codebook, 0, sizeof(codebook) * codebookSize);
pour codebookSize, lŕ .... c'est vous qui voyez . 256,1024,2048....ŕ vous de voir, selon l'image ŕ compresser....et du temps que vous voulez que ca prenne a calculer .
On a donc creer un code book, on l'a remis a 0 . En d'autre terme, on est pręt.
ce qui va suivre est un exemple de bestialite mathematique, une démonstration de ce que "brute force" veut dire.
Pour chacun des nos SQuant, on va trouver le vecteur dans le codebook(membre vector de SCodebookEntry) le plus proche de ce SQuant.
Ah ben je croyais qu'il etait vide, le codebook ?
Rigoureusement exact, mais ce que je n'ai pas (encore) dit, c'est que l'algorithme (qui s'appelle d'ailleurs Generalized Lloyd Algorithm, GLA pour les intimes) va s'effectuer en plusieurs passes . Donc ŕ la premičre, il est effectivement vide, mais aux suivantes il ne le sera plus
Reprenons . Donc pour trouver quel vecteur du codebook correspond le mieux, il nous faut calculer la distance entre les deux vecteurs, ce qui se fait par :
float distance = sqrt( ( quant.data[0] - entry.vector.data[0])˛ +
( quant.data[1] - entry.vector.data[1])˛ +
.....+( quant.data[11] - entry.vector.data[11])˛);
Notez que comme cette distance n'est lŕ qu'ŕ titre de comparaison, on se fout bien de la sqrt . Vous pouvez donc la degager tranquilement.
Maintenant, pour trouver quelle entrée du codebook est la bonne, ca va ętre un truc du genre :
for (int i=0;i< widthQ * heightQ;i++)
{
float distance;
SCodebookEntry *c = findClosest(quant+i,&distance); //cherche le vecteur dans le codebook le plus proche
c->nbHit++; //augmente le nombre de "hit" dudit vecteur
addVector( c->totalVector,quant[i]); //et dans la foulée on ajoute le vecteur courant au champ
//totalvector du codebookEntry choisi (expl later)
if (c->maxDistance < distance) //pour la suite on va aussi avoir besoin
{ //du point le plus eloigne pour chaque codebookentry
c->maxDistance = distance; //donc la on en garde une trace, aussi
c->farthest = quant[i];
}
}
avec :
SCodebookEntry * findClosest(SQuant * quant,float * distance)
{
float distanceMin,tmpdistance;
distanceMin =50000000 ; //truc bidon, mais gros
int index;
for (int i=0;i< codebookSize;i++)
{
tmpDistance = vectorDistance(codebook[i].vector,quant); //calcul la distance entre les deux vecteurs
if (tmpDistance < distanceMin) //si c'est plus proche....
{
distanceMin = tmpDistance; //...alors on maj nos variables et
index = i; //on stocke l'indice
}
}
*distance = distanceMin;
return codebookSize+index;
}
Récapitulons :
Pour chaque SQuant (block de pixel, donc) :
- trouver codebookentry qui correspond le plus
- ajouter le quant courant au codebook entry
finPour
et que faire une fois que l'on a fait tout ca ?
on va affiner notre codebook, pardi ! (ou foutredieu, si vous ętes du genre plus grossier)
Pour cela on va tout simplement calculer le vecteur moyen pour chaque entrée (c'est pour cela que l'on garde trace du nombre de vecteur ajoutés (nbHit) et des vecteurs ajoutés (totalvector)
Affinons donc :
for (int i=0;i < codebooksize;i++)
{
codebookEntry[i].vector = codebookentry[i].totalVector / codebookEntry[i].totalHit
}
codebookEntry[i].vector sera donc le vecteur "final" du codebook. Joie !
Mais...
Si une entrée ŕ 0 hits, ca veut qu'elle sert a rien . De la place perdue donc ! (et une division (12, męme) par 0 dans le code juste au dessus si on fait pas gaffe)
ce qui ne va pas du tout.
Alors dans ce cas de figure, on va "relocaliser" l'entrée vide. On va scanner toutes les codebook entry, et celle qui a le plus grand champ distanceMax" va nous servir pour relocaliser l'entree vide .(si elle a un grand champ max, cela veut dire que l'erreur entre ensemble de depart et ensemble final est grande . Il s'agit donc d'une zone a affiner, si vous me suivez)
ce qui nous donne donc :
for (int i=0;i < codebooksize;i++)
{
if (codebookEntry[i].nbhit != 0)
codebookEntry[i].vector = codebookentry[i].totalVector / codebookEntry[i].totalHit;
else
{
codebookEntry *q = findfarthest();
codebookEntry[i].vector = q->farthest;
q->distanceMax = 0; //on remet a 0 histoire de disqualifier cette entree lors de potentielles recherches ulterieure
}
}
vouala
Une fois le refinage fait, on remet les champs distanceMax,totalvector,farthest et nbhit de toutes les entrées du codebook ŕ 0 et...on recommence tout
Bon, on a pas que ça ŕ faire dans la vie que de raffiner du codebook . Il va falloir se définir une (voir męme plusieurs) condition d'arręt
La premiere est évidente : si on ne modifie plus de vecteur, alors c'est bon . On a fini .
Tant qu'a y ętre, plutot que de faire un bete if (codebookEntry[i].vector == codebookentry[i].totalVector / codebookEntry[i].totalHit), calculez plutôt la distance entre les deux . Si inférieur ŕ EPSILON (que je vous laisse choisir..) alors on peut les considérer comme égaux .
Voila pour la premičre condition.
Malheureusement, c'est pas aussi simple ... il y a de fortes chances que si vous modifiez un vecteur ŕ une passe x, en x+1 ce vecteur ne changera pas, mais un autre, si. et quand vous modifierez l'autre alors ça va rebricoler sur le premier et....
On ne s'en sort pas .
La seconde, qui nous vient tout droit du gars qui ŕ ecrit l'article sur gamasutra, c'est de se faire un petit tableau qui contient les 10 derniers nombres de vecteurs modifiés (au début, le tableau est initialisé avec de grands chiffres) . Si le plus grand chiffre de ce tableau est inférieur ŕ 1 de la taille du codebook, alors on arręte de bosser
Enfin, une troisičme, toute con, c'est de limiter le nombre de passe...(j'osais pas trop la sortir, mais sait-on jamais)...
Allez, derničre ligne droite, on ŕ fait le plus dur (qui n'etait pas si dur que ça, non ?)
Tout ce qu'il nous reste a faire, c'est pour chaque SQuant trouver le vecteur du codebook qui lui est le plus proche et sauver l'indice dudit vecteur
(genre si le vecteur du codebook qui colle le mieux au SQuat courant est le numero 10, ben vous sauvez 10)
Etant donné que tout ce dont vous avez besoin pour faire cela c'est la fonction distance entre deux vecteurs, je ne develope pas plus.
Au début de la doc j'ai choisi des blocks de 2x2 pixels. C'est un choix qui donne de bons resultats . L'article dans gamasutra utilise une pattern de 4x1, pour la bonne et simple raison qu'avec une pattern de ce type, la décompression se fait franchement vite (mais c'est au prix d'un peu de qualite), vu que vous n'avez qu'a recopié les blocks de pixel contenus dans le codebook de maničre linéaire (indice 10 ? hop, je recopie direct et sans réfléchir l'entrée 10 du codebook)
Bien, prenons une image au hasard :

et passons la au VQ avec différentes taille de codebook (pattern 2x2) :
respectivement :
32 256
1024 2048
En 32, ca vaut ce que ca vaut . Mais avec un codebook de cette taille lŕ, pour peu que l'image soit un peu remplie de couleurs il ne faut quand meme pas trop s'attendre a grand chose . Un peu palotte les couleurs, avec ca.
A partir de 256, ca devient correct, sauf au niveau du nez/casquette/chaines . Les tailles supérieures, 1024 et 2048 ajoutent des détails, pour finalement arriver ŕ une image tres proche de l'originale.
Bon, pas besoin d'ętre grand gourou pour voir que tout cela, ça risque de prendre du temps, surtout avec de grandes images qui risquent d'avoir besoin d'un gros codebook (en plus d'avoir plein de SQuant)
Il y a quand męme un truc a voir, c'est que notre fonction "vectorDistance" va ętre appelée un sacré paquet de fois (de meme que la fonction add). Par exemple, pour une image 256x256 avec un codebook de 1024, elle ne sera appelée pas moins de 1024*128*128 fois par passe (16777216, au cas ou vous demanderiez combien cela fait)
Donc, premičre chose ŕ faire, inliner ces fonctions . Ca coute pas cher et c'est toujours cela de pris.
La deuxieme chose a voir, c'est que tout cela a bien une bonne tęte de candidat pour le SIMD (3dnow!, SSE) . Et sans ętre un master de l'assembleur, convertir ces fonctions pour qu'elles utilisent le 3dnow! ne devrait pas poser de gros problčmes...
Preuve par l'exemple :
__forceinline float vectorDistance3dnow(SQuant *src,SQuant *src2)
{
_asm
{
mov eax,src;
mov ecx,src2;
//copie du premier quant dans les registres MMX / 3dnow
movq mm0,[eax];
movq mm1,[eax+8];
movq mm2,[eax+16];
movq mm3,[eax+24];
movq mm4,[eax+32];
movq mm5,[eax+40];
//soustraction des deux vecteurs
pfsub mm0,[ecx];
pfsub mm1,[ecx+8];
pfsub mm2,[ecx+16];
pfsub mm3,[ecx+24];
pfsub mm4,[ecx+32];
pfsub mm5,[ecx+40];
//mise au carre
pfmul mm0,mm0;
pfmul mm1,mm1;
pfmul mm2,mm2;
pfmul mm3,mm3;
pfmul mm4,mm4;
pfmul mm5,mm5;
//et addition de tout ca
pfacc mm1,mm0
pfacc mm2,mm1
pfacc mm3,mm2
pfacc mm4,mm3
pfacc mm5,mm4
pfacc mm5,mm5;
movd eax,mm5
}
}
vouala...meme si c'est pas forcement ce qu'il se fait de mieux ça devrait deja accélérer les choses..
Reste l'addition et la multiplication par un scalaire, mais bon, vous etes grand hein ?
C'est une autre question qu'il nous faut regler . Il faut arriver a trouver un bon compromis entre taille du codebook (le plus petit, le mieux) et qualité finale de l'image.
Le monsieur qui a écrit la doc sur gamasutra indique qu'ils calculent différentes versions de l'image avec un codebook de plus en plus gros et ensuite ils choisissent la version offrant le meilleure rapport taille / qualité.
Bonne méthode (peut ętre un peu violente), surtout si on peut l'automatiser....et c'est ce que nous allons faire maintenant
Pour cela il nous faut une methode qui nous permettra de calculer le taux de ressemblances entre deux images .Et ca, c'est la deuxičme partie de cette doc. Bon, au boulot !
Note : La methode qui va suivre est plutôt basique et ne marchera que parce que les images sont deja trčs proches a la base . Si vous lui donnez une photo de titi votre chat et de tata le chat de votre voisine, esperez pas grand chose, sous peine de violente déception.
Bon, prenons deux images noires et blanc :
Sur la gauche notre image de base convertie en noir & blanc, sur la droite l'image de base compressée avec un codebook de 256, puis convertie en noir et blanc par paint shop pro
D'un autre coté prenons un histogramme 2d, vierge pour le moment.(ledit histogramme n'etant rien d'autre qu'un tableau a deux dimensions, de taille 256x256 . 256 car nous avons 256 niveaux de gris)
Maintenant, prenons la couleur du pixel (0,0) de la premičre image (c1) et celle de du pixel(0,0) de la deuxičme image (c2)
(pour le moment, vu que l'on est en noir et blanc, il n'y a qu'une composante, codee sur 8bits)
hop, on va en case (c1,c2) de notre histogramme et on ajoute 1 a cette case.
et on fait de meme pour tous les pixels
voila l'histogramme ainsi obtenu :

Si les deux images sont identiques alors c1=c2 pour tous les pixels. Et donc, seule la diagonale de l'histogramme serait visible .
Cet histogramme est interessant, il va nous permettre de calculer une valeur nommée "mutual information" ( plus précisement, "normalized mutual information"). Valeur qui passe par le calcul d'entropie
La normalized mutual information a pour formule :
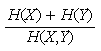
H(X) et H(Y) sont les entropies marginales, H(X,Y) l'entropie jointe.
L'entropie marginale d'une variable aléatoire X se calcule grâce ŕ cette jolie formule :
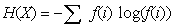
f(i) étant la probabilité qu'un pixel de l'image X ait l'intensité i .
Calculons H(X). Il va falloir dans un premier temps projeter l'histogramme sur X (ceci va nous donner un tableau a 1 dimension, de taille 256) . La projection se fait simplement en additionnant les elements d'une colonne donnée . Par exemple, pour la colonne 0:
float value = 0;
for (int i=0;i < 256;i++)
{
value += histo2d[i][0];
}
Ensuite calcul de la contribution a l'entropie :
if (value)
{
float pX= value / (float)(width * heiht);
HX -= pX*logf(pX);
}
Notre pX est le f(i) de la formule précédente .
Et ceci pour chaque colonne . en résumé :
float HX=0;
for (i = 0;i<256;i++)
{
float value=0;
for (int j=0;j<256;j++)
value+=lp2dHistogram[j][i];
if (value)
{
float pX= value / (float)(width * height);
HX -= pX*log(pX);
}
}
Hop, on a l'entropie marginale en X.
vous faite la meme chose en Y (au lieu de faire value+=lp2dHistogram[j][i] vous faites value+=lp2dHistogram[i][j], c'est a dire que vous projetez une ligne et non plus une colonne), vous stockez le tout dans HY et non dans HX et vous voila ok avec les entropies marginales.
A nouveau, une petite formule :
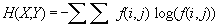
Pour remettre ca en clair, un peu de code :
float HXY = 0.0f;
for (i = 0;i<256;i++)
{
for (int j=0;j<256;j++)
{
float value=(float)lp2dHistogram[i][j];
if (value)
{
float pXY= value / (float) (width * height);
HXY -= pXY*log(pXY);
}
}
}
Voila, on a tout ce qu'il faut . reste plus qu'a appliquer la formule :
float result = (HX + HY) / HXY;
Si les deux images sont absoluments identiques, on obtient un résultat de 2 . Si elles n'ont rien a voir, alors on aura 1.
Mais, si en comparant deux images vous tombez sur des valeurs de l'ordre de 1.3 c'est déja qu'elles ont de grandes ressemblances (c'est du moins la valeur que j'ai choisi pour le choix du codebook, maintenant, vous faites comme vous le voulez).
Etant donné que l'on travaille non pas en noir et blanc mais en RGB il va falloir calculer trois valeurs (une par canal) . Le resultat final sera la moyenne de ces trois valeurs.
Revenons ŕ la création du codebook . en pseudo code, ca peut rendre :
entropie = 0;
codebooksize = 64;
tant que entropie < 1.3
compresserVQ(codebookSize);
calculer entropie;
codebooksize * = 2;
fin tant
(ou vous pouvez utiliser des méthodes de recherches plus fine, genre dichotomie)
Bon, ben, on a vu pas mal de truc d'un coup (si ca se trouve vous saturez autant que moi), et bon, si quelque chose n'est pas clair, ou vous avez des remarques / commentaires / améliorations : chrisbk@ifrance.com....
Have fun with VQ :)
thks a nico pour la relecture de cette doc





